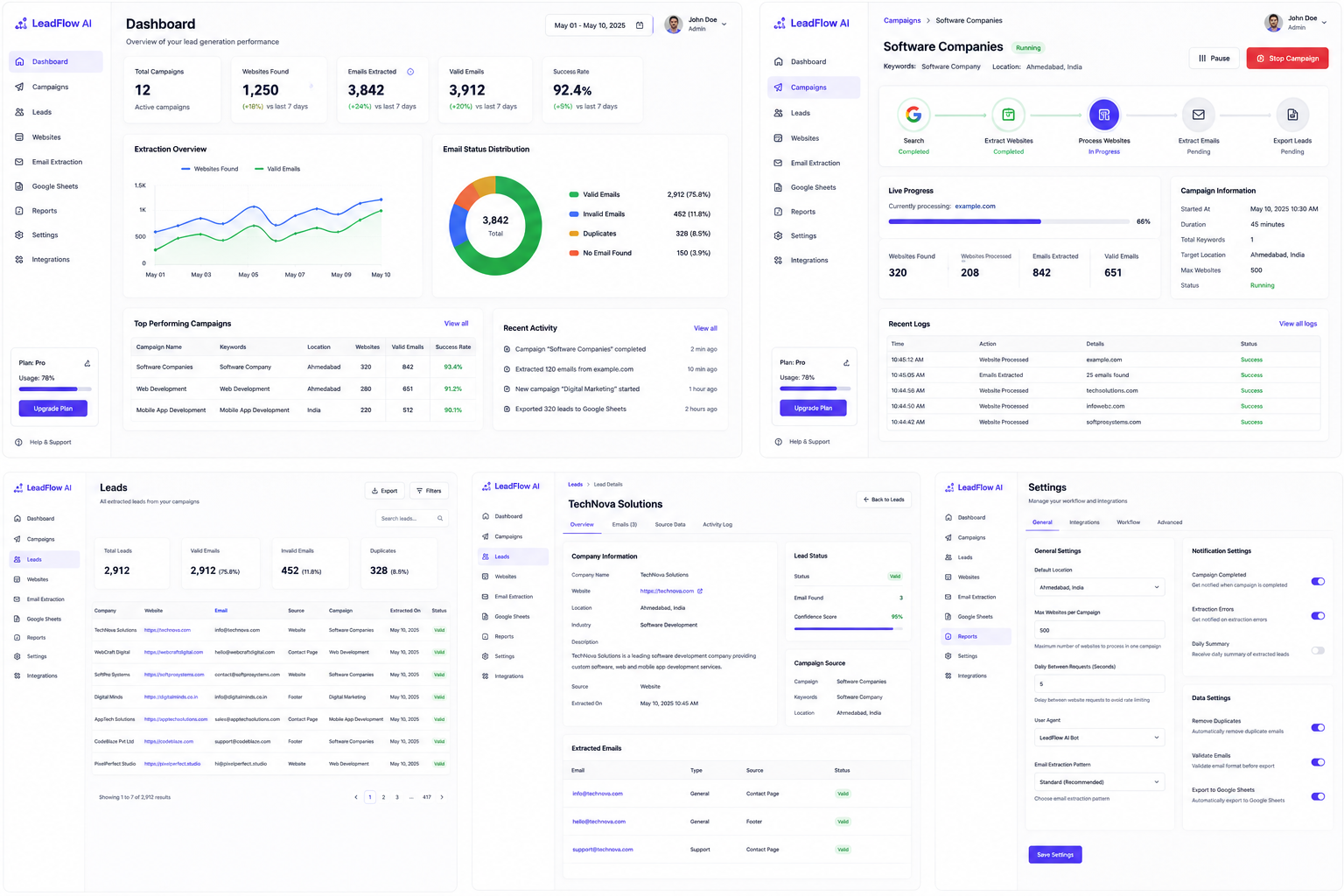
Purpose of the Lead Generation System
The system is engineered to automate business prospecting and outreach preparation. It eliminates manual directory lookup and contact verification, delivering a reliable, continuous stream of high-intent sales opportunities.
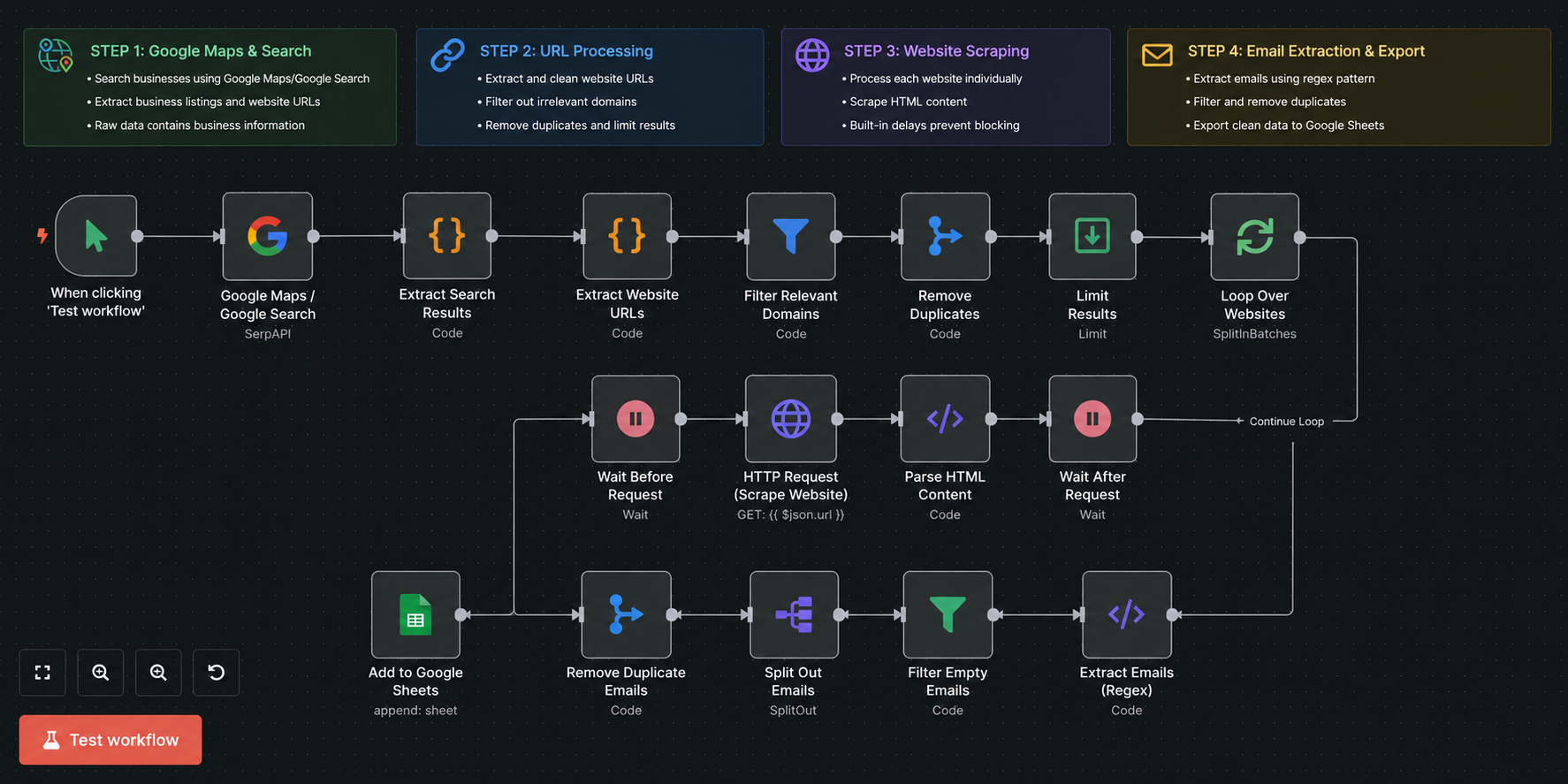
Google Search & Maps Scraping
The workflow utilizes SerpAPI to query Google Search and Google Maps for business listings matching specific industries, niches, or geographic coordinates. This gathers business metadata including physical addresses, telephone listings, and official domain URLs.
Website URL Extraction
The system extracts business website URLs from the search results, validating domains and standardizing them into primary formats for downstream scanning.
Link Filtering & Deduplication
To protect resource allocation, the workflow filters out irrelevant directory links, social media platforms, and duplicate company domains, passing only unique corporate websites to the scraper queue.
Individual Website Processing
Domains are processed individually and sequentially through n8n execution queues. This ensures isolated data collection, detailed logging, and precise error handling for each target business.
HTML Content Scraping
An HTTP request node fetches raw HTML content from the target homepage, about page, and contact page. The DOM structure is parsed to extract clean text blocks.
Regex Email Extraction
Advanced regular expressions (Regex) scan the extracted HTML text for email address patterns. This detects contact channels embedded in standard text, layouts, or metadata tags.
Email Cleaning & Deduplication
The system filters out invalid address formats, duplicate entries, and general catch-all aliases, retaining only primary, actionable communication channels.
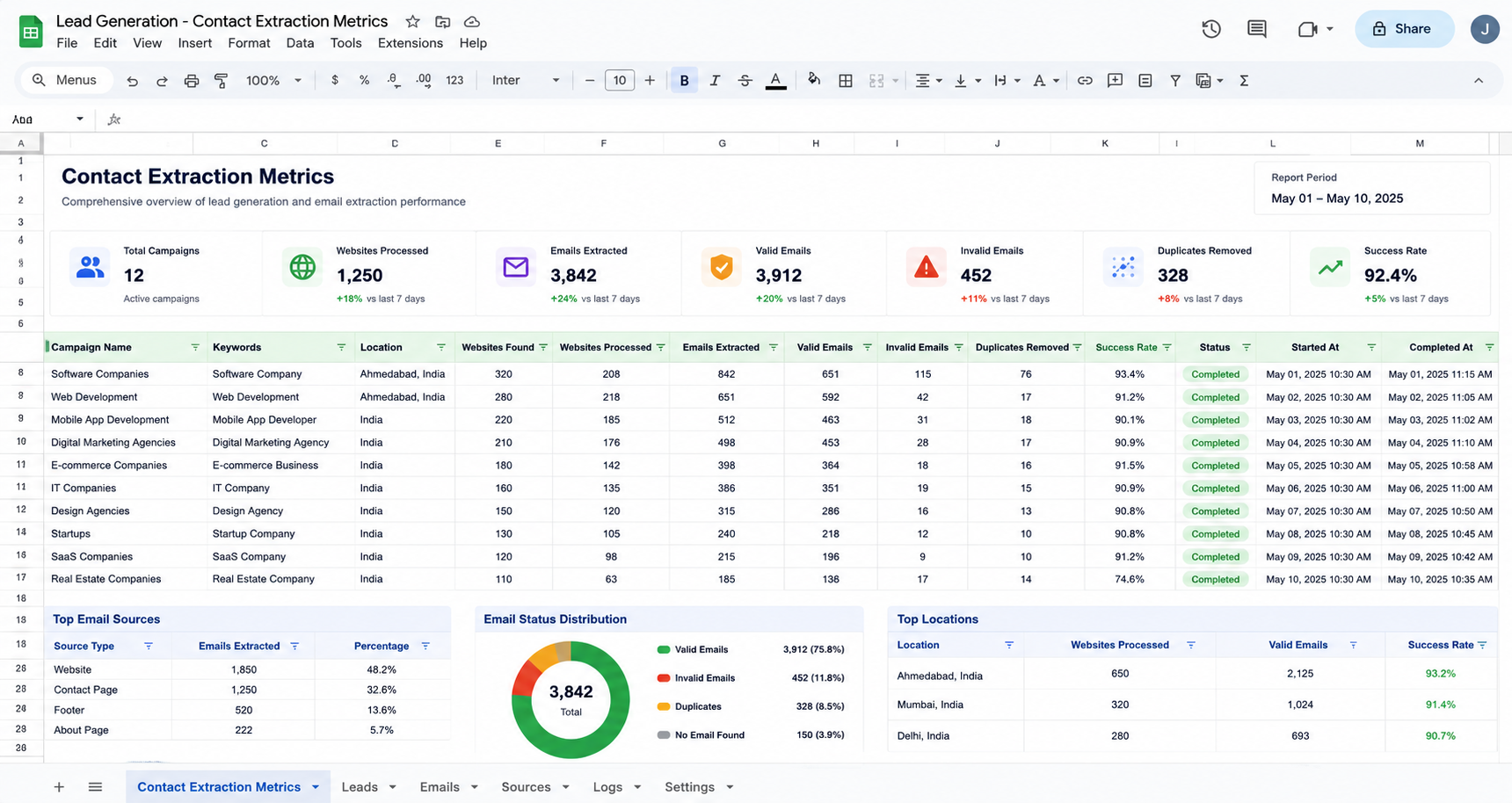
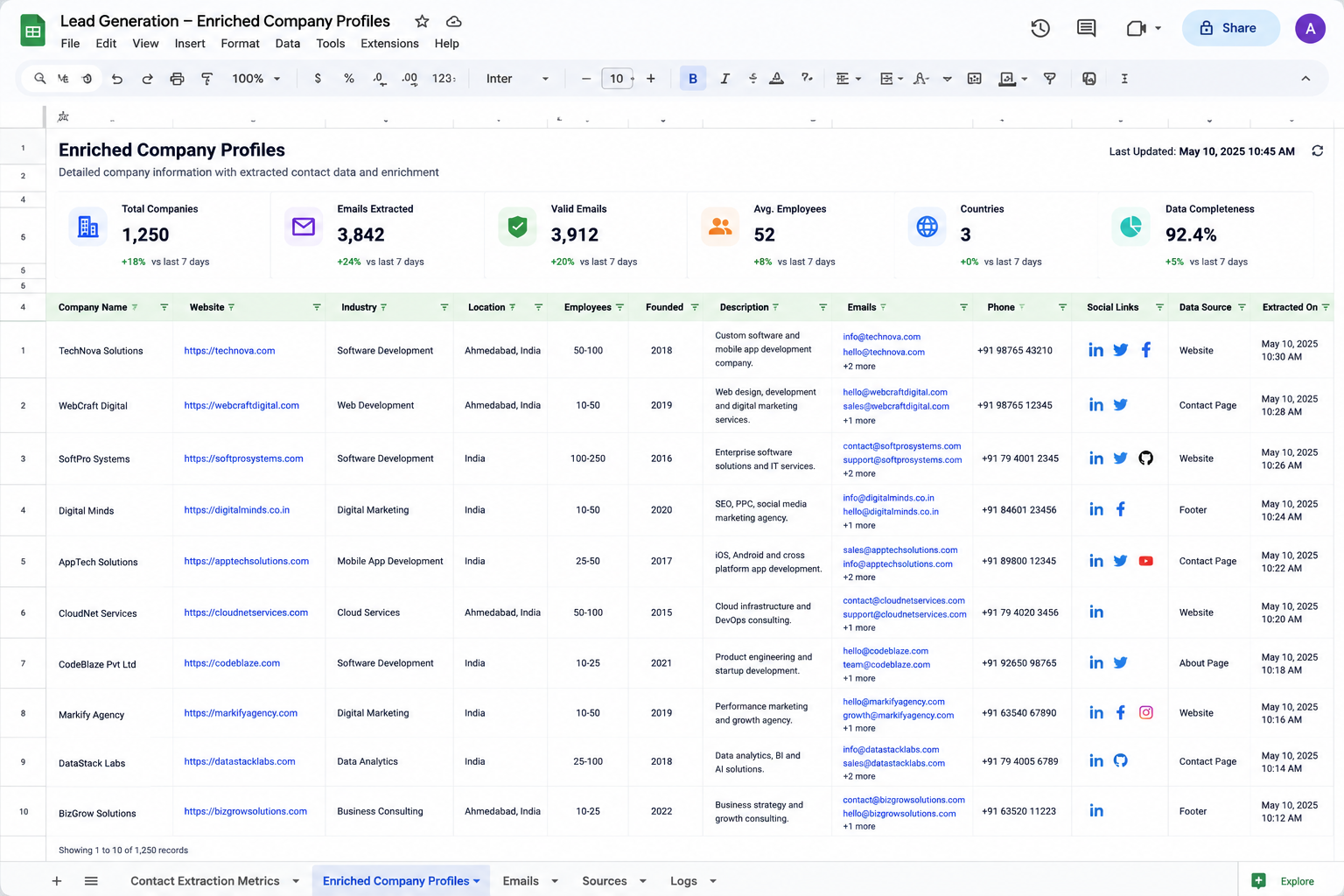
Clean Contact Dataset Generation
The pipeline aggregates verified emails, telephone numbers, social links, and metadata, generating a structured and unified contact card for each business.
Data Conversion into Structured JSON
The raw extracted properties are parsed and mapped into standard JSON schemas. This structures the data for reliable database writes and CRM synchronization.
Google Sheets Exporting
Using the Google Sheets API, the system appends the structured JSON records into specific columns, maintaining organized spreadsheet datasets in real-time.
Batching & Delay-Based Rate Limiting
The queue system applies configured batch sizes and time delays between requests. This prevents IP blocking, respects target server resource limits, and avoids API rate limiting.
Data Extraction Pipeline
The extraction pipeline converts search queries into actionable insights by handling API querying, HTML fetching, regex filtering, and database updates in a single continuous flow.
Prospecting & Outreach Automation
By capturing key company metrics and contact channels, the workflow generates clean data points that allow sales reps to prepare personalized sales pitches immediately.
Large-Dataset Scalability
The workflow supports high-volume execution, distributing processing tasks across queue systems to fetch thousands of local business records continuously.